
Two of the most under-appreciated Linux utilities are sed and awk. Although they can seem a bit arcane, if you ever have to make repetitive changes to large pieces of code or text, or if you ever have to analyze some text, sed and awk are invaluable.
So, what are they? How are they used? And how, when combined, do they make it easier to process text?
What Is sed?
sed was developed in 1971 at Bell Labs, by legendary computing pioneer Lee E. McMahon.
The name stands for “stream editor.” sed allows you to edit bodies or streams of text programmatically, through a compact and simple, yet Turing-complete programming language.
The way sed works is simple: it reads text line-by-line into a buffer. For each line, it’ll perform the predefined instructions, where applicable.
For example, if someone was to write a sed script that replaced the word “beer” with “soda”, and then passed in a text file that contained the entire lyrics to “99 Bottles of Beer on the Wall”, it would go through that file on a line by line basis, and print out “99 Bottles of Soda on the Wall”, and so on.
The most basic sed script is “Hello World.” Here, we use the echo command, which merely outputs strings, to print “Hello World.” But we pipe this to sed, and tell it to replace “World” with “Dave”. Self-explanatory stuff.
echo "Hello World" | sed s/World/Dave/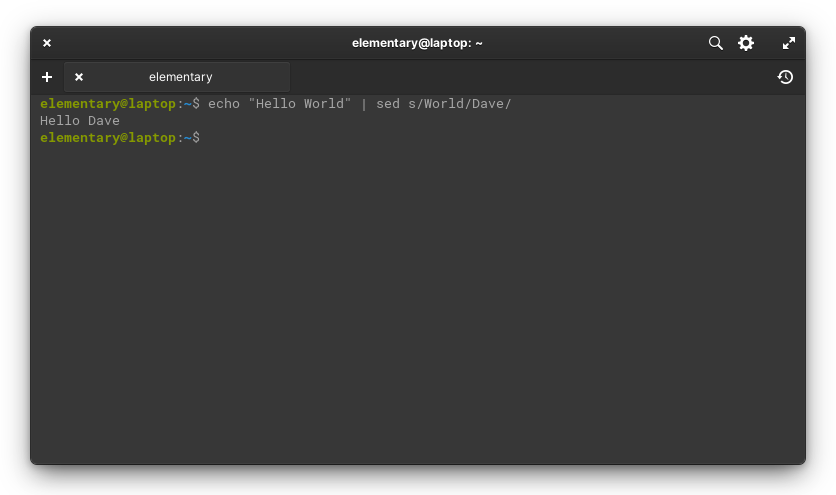
You can also combine sed instructions into files if you need to do some more complicated editing. Inspired by this hilarious Reddit thread, let’s take the lyrics to A-ha’s “Take On Me,” and replace each instance of “I”, “Me”, and “My”, with Greg.
First, put the lyrics to the song in a text file called tom.txt. Then open up your preferred text editor, and add the following lines. Ensure the file you create ends with .sed.
s/I/Greg/
s/Me/Greg/
s/me/Greg/
s/My/Greg/
s/my/Greg/
You might notice repetition in the example above (such as s/me/Greg/ and s/Me/Greg/). That’s because some versions of sed, like the one that ships with macOS, do not support case-insensitive matching. As a result, we have to write two instructions for each word for sed to recognize the capitalized and uncapitalized versions.
This won’t work perfectly, as though you’ve replaced each instance of “I”, “Me”, and “My” by hand. Remember, we’re just using this as an exercise to demonstrate how you can group sed instructions into one script, and then execute them with a single command.
Then, we need to invoke the file. To do that, run this command.
cat tom.txt | sed -f greg.sedLet’s slow down and look at what this does. You may have noticed that we’re not using echo here. We’re using cat. That’s because while cat will print out the entire contents of the file, echo will only print out the file name. You may have also noticed that we’re running sed with the “-f” flag. This tells it to open the script as a file.
The end result is this:
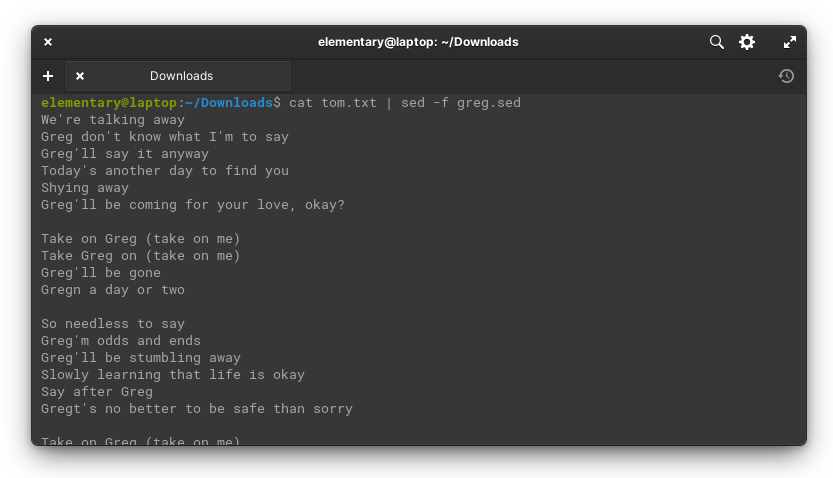
It’s also worth noting that sed supports regular expressions (REGEX). These allow you to define patterns in text, using a special and complicated syntax.
Here’s an example of how that might work. We’re going to take the aforementioned song lyrics, but use regex to print out every line that doesn’t start with “Take”.
cat tom.txt | sed /^Take/d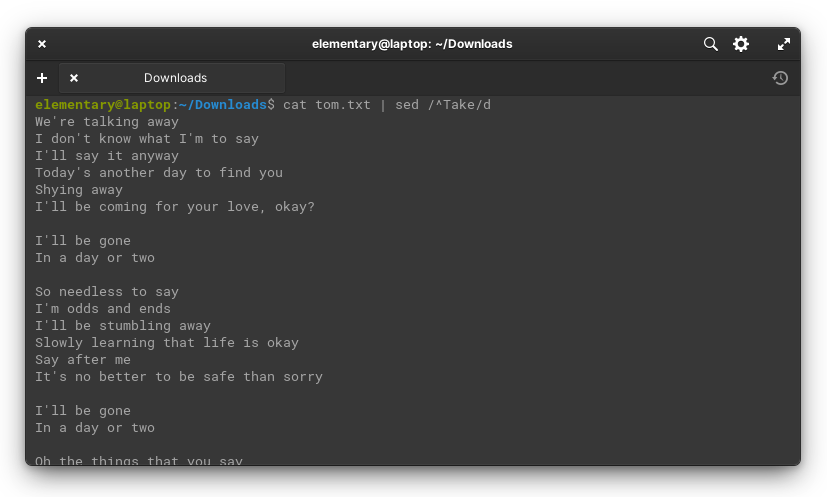
sed is, of course, incredibly useful. But it’s even more powerful when combined with awk.
What Is AWK?
AWK, like sed, is a programming language that deals with large bodies of text. But while people use sed to process and modify text, people mostly use AWK as a tool for analysis and reporting.
Like sed, AWK was first developed at Bell Labs in the 1970s. Its name doesn’t come from what the program does, but rather the surnames of each of the authors: Alfred Aho, Peter Weinberger, and Brian Kernighan. In all caps, AWK refers to the programming language itself. In lowercase, awk refers to the command-line tool.
AWK works by reading a text file or input stream one line at a time. Each line is scanned to see if it matches a predefined pattern. If a match is found, an action is performed.
But while sed and AWK may share similar purposes, they’re two completely different languages, with two completely different design philosophies. AWK more closely resembles some general-purpose languages, like C, Python, and Bash. It has things like functions and a more C-like approach to things like iteration and variables. Put simply, AWK feels more like a programming language.
So, let’s try it out. Using the lyrics to “Take On Me,” we’re going to print all the lines that are longer than 20 characters.
awk ' length($0) > 20 ' tom.txt
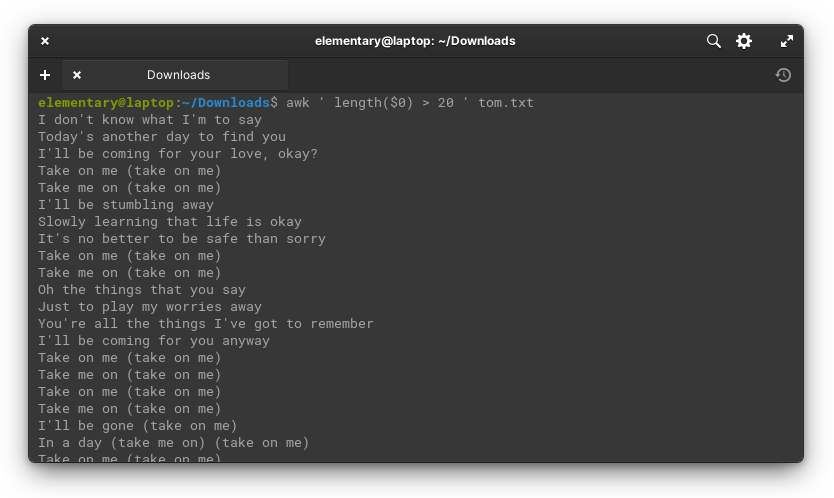
Combining the Two
awk and sed are both incredibly powerful when combined. You can do this by using Unix pipes. Those are the “|” bits between commands.
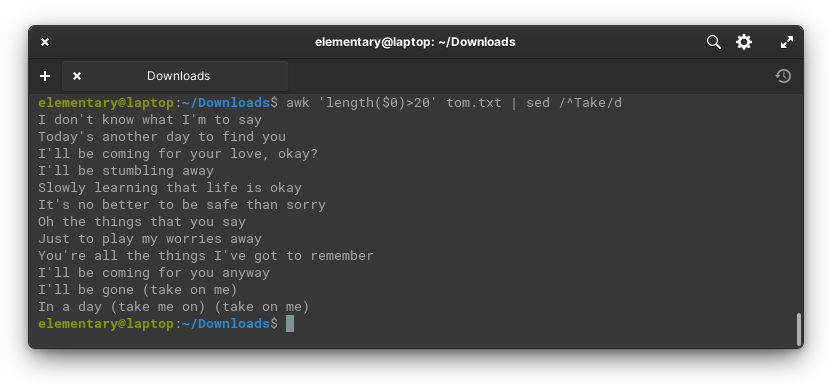
Let’s try this: we’re going to list all the lines in “Take On Me” that have more than 20 characters, using awk. Then, we’re going to strip all the lines that begin with “Take.” Together, it all looks like this:
awk 'length($0)>20' tom.txt | sed /^Take/dAnd produces this:
The Power of sed and awk
There’s only so much you can explain in a single article, but hopefully, you now have a feel for how immeasurably powerful sed and awk are. Simply put, they’re a text-processing powerhouse.
So, why should you care? Well, besides the fact that you never know when you need to make predictable, repetitive changes to a text document, sed and awk are great for parsing log files. This is especially handy when you’re trying to debug a problem in your LAMP server or looking at your access logs to see whether your server has been hacked.
Read Next
About The Author